Kicsit régebben ígértem, hogy a collationökre még visszatérek. Eljött az idő.
Leszedtem a Posta weblapjáról az éppen aktuális irányítószám-listát, és feltöltöttem egy adatbázisba. Nem az egészet, csak egy darabját, viszont azt egyből többször is: nagybetűsen és kisbetűsen is szerepelnek benne az adott települések, valamint kicsit ékezettelenítve is.
Az adatbázison magyar környezetben üzemel, ezért az alap collationje a hungarian_ci_as, vagyis magyar, case insensitive (nem érdekli a kisbetű-nagybetű) és accent sensitive (az ékezeteket figyelembe veszi).
Az alap lekérdezésem így néz ki:
select irszam, telepules from irsz where irszam = '7695' order by telepules;
Az eredménye pedig így:
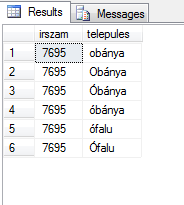
Látszik benne, hogy
- CI (a kisbetű-nagybetű nem számít): az obánya ugyan előbb van, mint az Obánya, de az Óbánya előbb van, mint az óbánya, vagyis nem alapban
- AS (ékezet számít): az Obánya minden variációja előbb van, mint az Óbánya
Teljesen ugyanez lesz a lekérdezés eredménye, ha explicit meg is adjuk, hogy ezzel a collationnel kérjük az adatokat:
select irszam, telepules from irsz where irszam = '7695' order by telepules collate hungarian_ci_as;
Ezzel megvan a szintaxis is: a collation megadását leggyakrabban az order by részben használjuk. Vaduljunk kicsit! Magyarul kérdezzük le, de bináris rendezésben.
select irszam, telepules from irsz where irszam = '7695' order by telepules collate hungarian_bin;
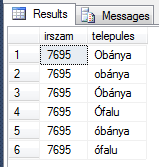
Egészen érdekes lett a sorrendünk, minden nagybetűs, ékezettelen került előre, majd az ékezettelek kisbetűs, aztán az ékezetes nagybetűs, végül az ékezetes kisbetűs. Ez azért van, mert ilyenkor a karakter-táblát veszi alapul, és akár ASCII-t nézünk, akár UTF8-at, a nagybetűk a kisbetűk előtt vannak, és az ékezettelen karakterek az ékezetesek előtt.
Kicsit játsszunk az ékezetekkel:
select irszam, telepules from irsz where irszam = '7695' order by telepules collate hungarian_cs_as;
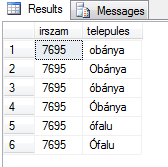
Az eredményen jól látszik, hogy most a case sensitive rész is előjött, tehát az ékezettelen adatok jönnek először.
Természetesen nem csak magyar collationt használhatunk, hanem sok félét, bár magyar adatbázison ez tűnik a legcélszerűbbnek. De azért érhetnek meglepetések.
Itt van ez a lekérdezés:
select irszam, telepules from irsz where telepules collate hungarian_ci_as like 'őrbott%';
Eredménynek nem ad ki semmit. Hogy miért? Mert Őrbottyánra szeretnénk keresni, és magyarban a tty egy dupla ty betűt jelöl. Nem egy t, majd egy ty, nem egy t, még egy t és egy y, hanem dupla ty. A fenti meg olyan településeket keres, ahol dupla t van. A magyar szabályok szerint Őrbottyán nem ilyen település.
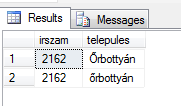
Ellenben ha kifejezetten nem magyarral kérdezzük le, ahol nincs ez a megkötés:
select irszam, telepules from irsz where telepules collate Latin1_General_CI_AI like 'őrbott%'
Akkor lesz eredményünk, mert ebben az esetben a latin1 szabályok szerint nincs ty betű, hanem simán t-re, t-re, y-ra bontja, és úgy keres.
Remélem ezzel sikerült kicsit megvilágítani, hogy mire jó a collation, hogyan használjuk és mire figyeljünk.