Mindenki ismeri a joinokat, ezek közül is persze legjobban az inner joint. Elém került egy lekérdezés, amiben volt pár inner join és a lekérdezés végén néhány szűrés. A feladat az volt, hogy gyorsítsam fel a lekérdezést, amit az execution plan tüzetesebb vizsgálatával talán el tudunk érni.
Első menetben természetesen megnéztem az indexeket, van-e megfelelő és használható-e a lekérdezés során.
Második menetben pedig a joinok és szűrések feltételeit vettem kicsit górcső alá.
Vegyük példának ezt az egyszerű lekérdezést:
select * from dpaciens as p
inner join dvizsgalat as v on v.pid = p.pid
where v.stid = 7
Szándékosan leszedtem minden indexet a két tábláról, csak és kizárólag a PK-kat hagytam fent. Erre azért volt szükségem, hogy ne mindig 2 másodperc alatt adja ki az eredményt, mert azt nem lehet igazán összehasonlítani. Csak technikai maszturbációnak hatna, hogy milyen ügyesen megoldottuk, hogy kis munkával ugyanolyan gyorsan le tudjuk kérdezni a táblákat.
Ez a lekédezés a gépemen lefutott nagyjából két perc alatt. A STID egyébként a vizsgálat státuszára utal, ilyen lekérdezést a la natur sosem fogunk kiadni a rendszerben, ezért ez a két perc nem is olyan szörnyű.
Ránézésre minden rendben van, összekapcsol két táblát és az eredményből kiszűri a megfelelő sorokat.
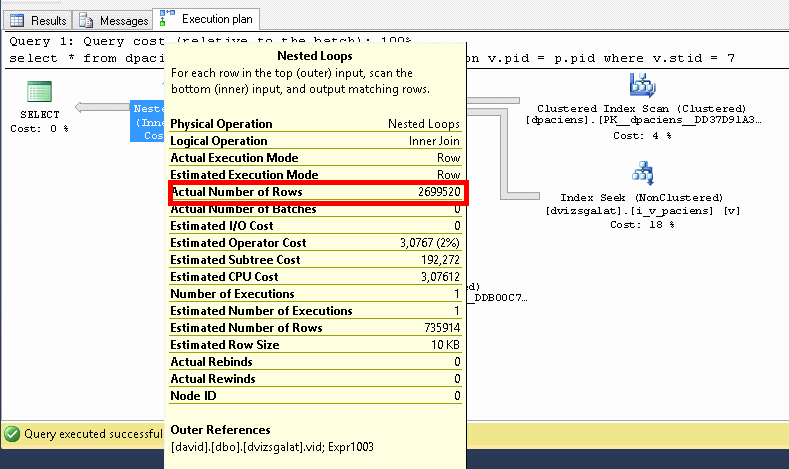
Ha megnézzük az actual execution plant, akkor látjuk is, hogy ezt teszi: veszi a dpaciens tábla tartalmát, veszi a dvizsgalat tábla tartalmát, összejoinolja, szűr, eredményt kiadja.
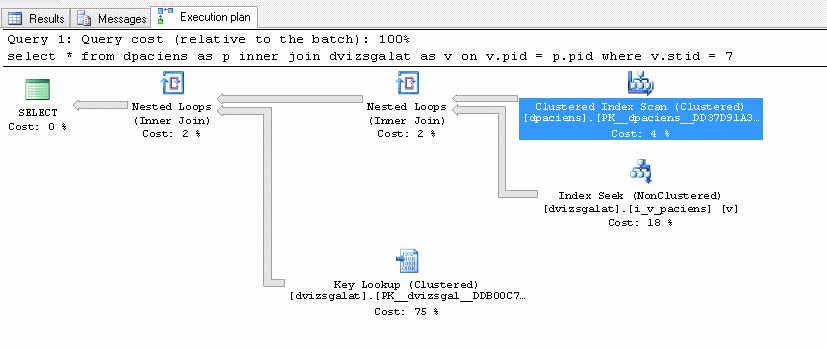
Nézzük csak meg jobban az első három lépést!
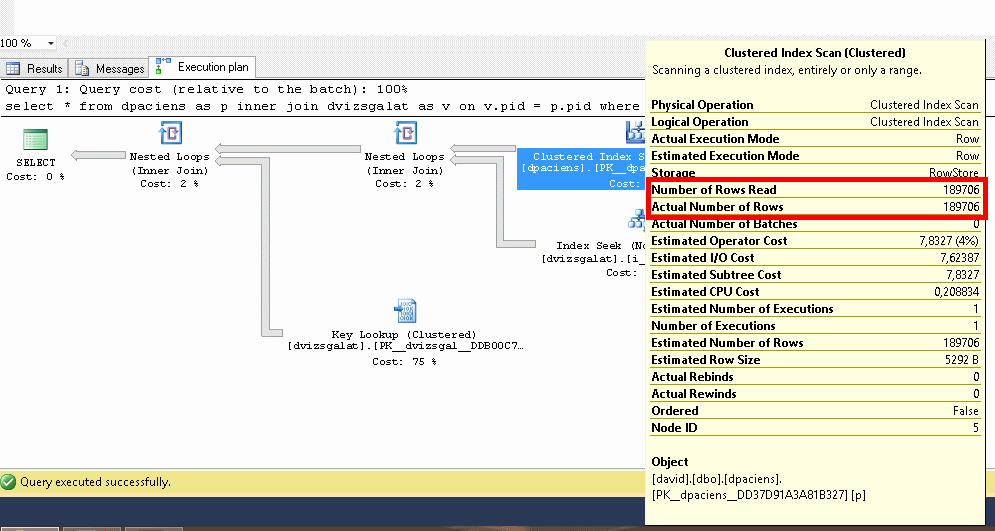
Clustered index scan a dpaciens táblára, érintett sorok száma 189.706, ami az összes sort jelenti.
Index seek a dvizsgalat táblára, érintett sorok száma 2.828.224, ami megint csak az összes sor a táblában. 
Ennek eredményeképpen a joinban szintén majdnem 3 millió rekord van még. 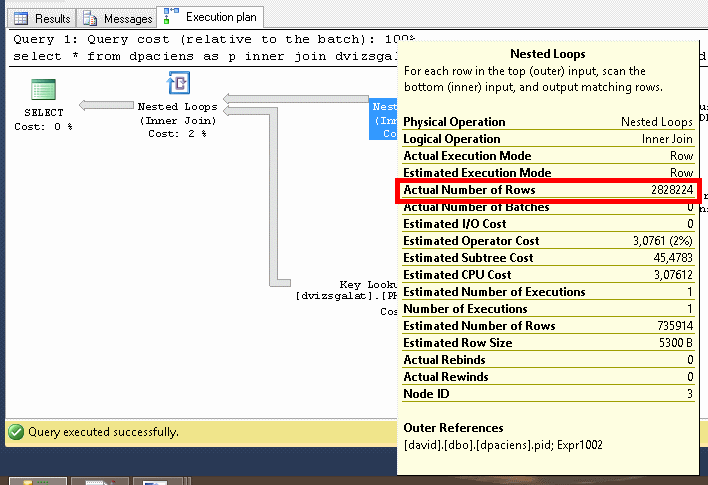
Közben lekérdezzük a dvizsgalat táblából azokat a sorokat, amik megfelelnek a szűrésünknek, és ezzel kiesik nagyjából 13 ezer rekord. Mindezt az index hiánya miatt 75%-os költség árán.
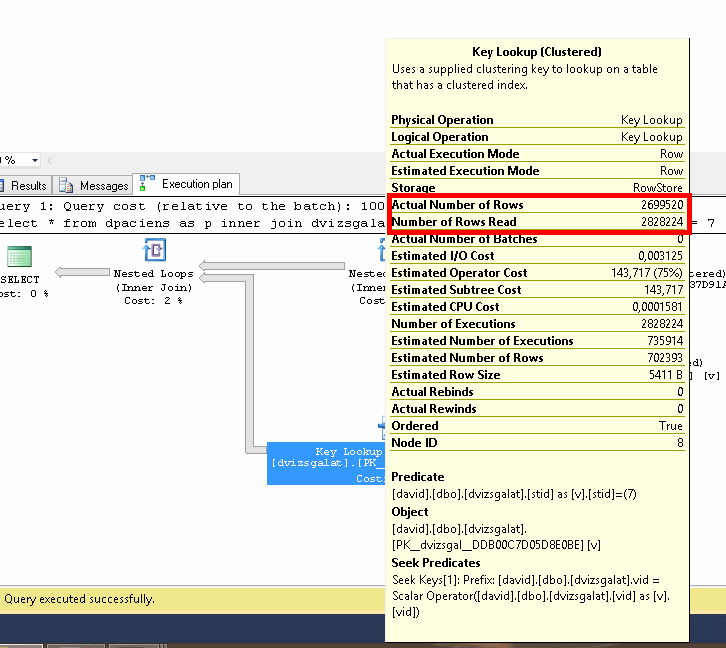
A következő lépésben az eredeti joinunk eredményét és a szűrt dvizsgalat azonosítók eredményét kapcsoljuk össze és ezzel kijön a végeredmény.
 Hogyan tuningoljuk meg? Tegyünk rá indexeket, szólal meg egyből a kisangyal a fejünkben. Tegyünk indexet a dvizsgalat pid oszlopára (jól jöhet a joinnál), meg az stid oszlopára (jól jön a szűrésnél). A költség százalékok nem biztos, hogy változni fognak, de hogy sokkal gyorsabb lesz a lekérdezésünk, az biztos.
Hogyan tuningoljuk meg? Tegyünk rá indexeket, szólal meg egyből a kisangyal a fejünkben. Tegyünk indexet a dvizsgalat pid oszlopára (jól jöhet a joinnál), meg az stid oszlopára (jól jön a szűrésnél). A költség százalékok nem biztos, hogy változni fognak, de hogy sokkal gyorsabb lesz a lekérdezésünk, az biztos.
De mi történjen akkor, ha nem tudunk rá indexet tenni? Akár azért, mert nincs rá jogosultságunk és a DBA nem teszi meg, akár azért, mert a dvizsgalat tábla újabb indexelése már erősen rontana az insert/update sebességén, és nekünk arra kellene fókuszálnunk?
Át tudnánk írni ezt az egyszerű lekérdezést úgy, hogy gyorsabb legyen, újabb indexek nélkül? Minden esetre megpróbálhatjuk. Sok mindent nem tehetünk, de mi van, ha a where feltételben levő részt a join feltételeihez mozgatjuk át?
Nem közkeletű, hogy ilyet lehet tenni, bár ha belegondolunk, teljesen logikus: ha meg tudunk adni két mezőt is összekapcsolásnak (on m1.mezo = m2.mezo and m1.mezo2 = m2.mezo2), akkor miért ne tudnánk megadni sima konstansokat tartalmazó feltételt is?
A fenti lekérdezésből ez lesz:
select * from dpaciens as p
inner join dvizsgalat as v on v.pid = p.pid and v.stid = 7
Az actual execution plan pedig szintén kicsit másképpen fog kinézni.
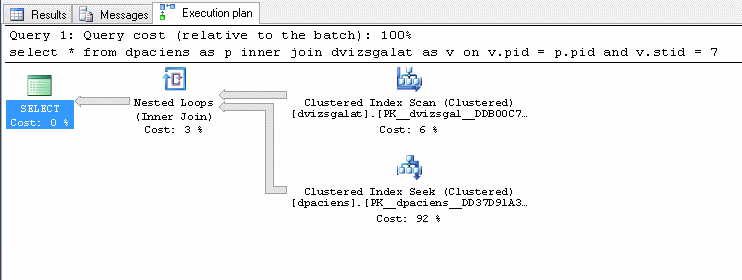
Ment egy clustered index scan a dvizsgalat táblára, de itt már alapban belevette a szűrést! Ezért a végén nem 2.82 millió, hanem 2.69 millió sort viszünk tovább.

A dpaciens természetesen megint kapott egy clustered index seeket, de itt most a másféle felépítés miatt 2.69 millió sorral dolgozik. 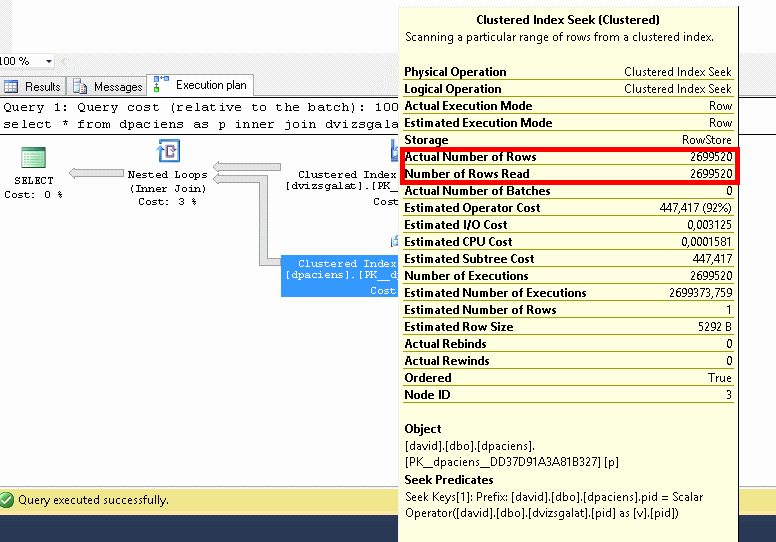
Maga az inner join már itt is villámgyors, és az eredmény lejött másfél perc alatt.
Még mindig nem egy villám, de egy egyszerű join-módosítással nyertünk fél percet, 25%-ot időben. Ezért már érdemes megvizsgálni ezt a lehetőséget is.
Ez a módszer nem vezet mindig eredményre, sőt, sok esetben a query analyzer van olyan okos, hogy a szűrést még a join előtt végzi el és így nem érünk el semmit.
Arra sajnos még nem jöttem rá, hogy mi alapján végzi a szűrést a join közben, és mi alapján utána, de egy próbát általában megér.
Akkor sem hoz eredményt, ha a joinnál a plusz feltételbe túl sok oszlopot veszünk fel, nem csak egyszerű összehasonlításokat adunk meg, vagy nem-egyenlőségi szűrőket is teszünk hozzá.
Ahogy minden más, ez is nagyon helyzetfüggő. Itt csak egy általános elvet írtam le, amit a megfelelő környezetben alkalmazva előnyre tehetünk szert. De mindig a helyzettől függ és az execution plan nézegetése erősen ajánlott minden lépés alkalmával.