
Megint belefutottam egy első ránézésre értelmetlen lassulásra. Nem a várt sebességgel futott egy nem túl bonyolult query, amiben csak pár join, egy nagyon egyszerű szűrés és egy rendezés volt.
Tüzetesebb vizsgálattal viszont már kibújt a lóláb, de szerencsére a javítás nagyon egyszerű volt, így utólag belegondolva. A kérdéses rész így nézett ki:
LEFT JOIN [OrderItem] oi
on o.OrderId = oi.OrderId
AND ISNULL(oi.Tag, '') <> 'S'
Első olvasatra nem tűnt fel, hogy az ISNULL a problémás. Ha bármilyen funkciót használunk az összekapcsolásnál, akkor az nem tud az indexek mentén működni, hiszen minden egyes sorra ki kell értékelnie a függvény értékét.
Amíg kevés adat volt, addig nem okozott gondot, kiköhögte az eredményt. Amint viszont elért egy kritikus tömeget, már egy percen kívül volt a visszatérési ideje, ezért kódból meghívva timeoutra futott. Megvizsgálva az execution plant egyből láttuk, hogy ez egy index scan és 18 millió rekorddal dolgozik:
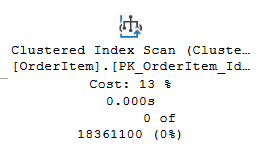
Amint erre ráébredtünk és a homlokunkra csaptunk, a megoldás már egyszerű volt.
LEFT JOIN [OrderItem] oi
on o.OrderId = oi.OrderId
WHERE ISNULL(oi.Tag, '') <> 'S'
A joint hagytuk szépen hagy fusson le gyorsan, ahogy csak tud, és a plusz feltételt a szűrés részbe helyeztük át. Az execution plant megvizsgálva is nagy a különbség:
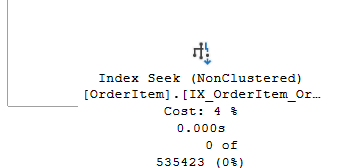
Ugyan egy másik indexet veszi figyelembe, de már seeket használ, és már csak 535 ezer sort használ. Így utólag teljesen egyértelmű, sajnos elvesztünk a nem fontos részletekben, de azért megvolt egy fél óra alatt.