
Mindig legyen. Röviden ennyi, aki eddig is így tett, azok csak ismétlésként olvassák át, akik nem így tettek, azoknak tanulságos lesz a lenti kifejtés.
Képzeljünk el két táblát. Az egyikben felhasználók vannak, mondjuk a tábla neve felhasznalo, primary key az id oszlop. A másikban valami extrát tárolunk a felhasználókhoz, tehát egy-többes kapcsolat van a két tábla között és itt is az id oszlop a primary key.
create table felhasznalo (
id int,
nev nvarchar(32) not null,
constraint pk_felhasznalo primary key clustered (id)
);
insert into felhasznalo(id, nev)
select 1, 'Nev1' union
select 2, 'Nev2' union
select 3, 'Nev3' union
select 4, 'Nev4' union
select 5, 'Nev5';
create table felhasznalo_valami (
id int,
-- egyeb oszlopok
constraint pk_felhasznalo_valami primary key clustered (id)
);
insert into felhasznalo_valami(id)
select 2;
Egy lekérdezésnél valamiért IN-re van szükségünk és nem joint használunk:
select nev from felhasznalo
where id in (select id from felhasznalo_valami);
Az eredmény egyértelmű: Nev2
Készítsünk egy harmadik táblát, ami olyasmi, mint a második, csak nem id-nek hívjuk az azonosító oszlopát, hanem valami másnak:
create table felhasznalo_valami2 (
felhasznalo_id int,
-- egyeb oszlopok
constraint pk_felhasznalo_valami2 primary key clustered (felhasznalo_id)
);
insert into felhasznalo_valami2(felhasznalo_id)
select 2;
Majd futtassuk le a fenti lekérdezést erre a táblára átírva:
select nev from felhasznalo
where id in (select id from felhasznalo_valami2);
Az eredményre pedig elkerekedhet a szemünk: Nev1, Nev2, Nev3, Nev4, Nev5.
De hogy a fenébe lehet ez? A mi logikánk szerint a lekérdezésnek kapásból hibát kellene dobnia, hiszen a felhasznalo_valami2 táblában nincs is id oszlop. Mégsem dob hibát, sőt, kiadja az összes oszlopot.
Ha megnézzük az execution plant, akkor újabb meglepetés ér minket. Felhasznalo tábla estimated number of rows to read: 5, number of rows read: 5; felhasznalo_valami2 tábla estimated number of rows to read: 1, number of rows read: 5.
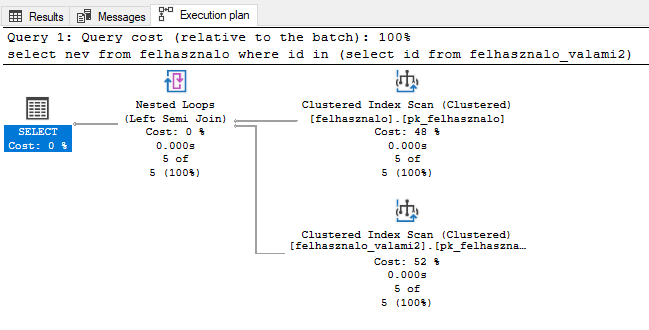
Tessék? Nézzük csak tovább azt az execution plant… A következő az IN, amit az execution plan úgy nevez el, hogy left semi join. Itt van a kutya elásva! Ezt a lekérdezést belül egy left joinnak fordítja le az értelmező és itt keverednek össze az oszlopok. Nincs alias a táblákon, ezért valami ilyesmit hoz ki belőle:
select nev from felhasznalo
left outer join felhasznalo_valami2 on id = id;
Így már teljesen érthető az eredmény. A megoldást szerintem már lelőttem a bejegyzés elején, mindenki rájöhet, hogyan küszöböljük ki. Használjunk aliast vagy használjunk joint:
select nev from felhasznalo as f
where f.id in (select fv.id from felhasznalo_valami2 as fv);
select nev from felhasznalo as f
inner join felhasznalo_valami2 as fv on f.id = fv.id;
Mindkét módszerrel egyből kiderül, hogy valami nem stimmel az oszlopainkkal.
Msg 207, Level 16, State 1, Line 5
Invalid column name 'id'.
Msg 207, Level 16, State 1, Line 8
Invalid column name 'id'.